{kind=link}
Note : High Concurrency clusters do not automatically set the auto shutdown field, whereas standard clusters default it to 120 minutes. There is no additional cost for using the Quick Start. Databricks is a unified data-analytics platform for data engineering, machine learning, and collaborative data science. This website uses cookies to analyse traffic and for ads measurement purposes. A lower value will cause more interactive response times, at the expense of cluster efficiency. The Quick Start sets up the following, which constitutes the Databricks workspace: To deploy Databricks, follow the instructions in the deployment guide. Uses the Databricks URL and the user bearer token to connect with the Databricks environment.
 Some of the settings, such as the instance type, affect the cost of deployment. Static (many workers new) The same as the default, except there are 8 workers. You are responsible for the cost of the AWS services used while running this Quick Start. To push it through its paces further and to test parallelism I used threading to run the above ETL 5 times, this brought the running time to over 5 minutes, perfect! We're are hiring for a to join our UK team Its been an exciting few months for Talent Acquisition and the People team at Adatis. This VPC is configured with private subnets and a public subnet, according to AWS best practices, to provide you with your own virtual network on AWS. Check out our Power BI as a Service today hubs.la/Q01gDsyb0
Some of the settings, such as the instance type, affect the cost of deployment. Static (many workers new) The same as the default, except there are 8 workers. You are responsible for the cost of the AWS services used while running this Quick Start. To push it through its paces further and to test parallelism I used threading to run the above ETL 5 times, this brought the running time to over 5 minutes, perfect! We're are hiring for a to join our UK team Its been an exciting few months for Talent Acquisition and the People team at Adatis. This VPC is configured with private subnets and a public subnet, according to AWS best practices, to provide you with your own virtual network on AWS. Check out our Power BI as a Service today hubs.la/Q01gDsyb0  Click here to return to Amazon Web Services homepage, Deploy a Databricks workspace and create a new cross-account IAM role, Deploy a Databricks workspace and use an existing cross-account IAM role.
Click here to return to Amazon Web Services homepage, Deploy a Databricks workspace and create a new cross-account IAM role, Deploy a Databricks workspace and use an existing cross-account IAM role.  Therefore, will allow us to understand if few powerful workers or many weaker workers is more effective. # Pivot the decade of birth and sum the salary whilst applying a currency conversion. Product information "Databricks: Automate Jobs and Clusters". If we are practicing and exploring Databricks then we can go with the Standard cluster. databricks spark hadoop yarn apache hdfs databricks standalone cluster read together working systems insidebigdata I included this to try and understand just how effective the autoscaling is. This event is open to women at all stages of their career who are interested in learning more about a tech role or company. Databricks pools enable us to have shorter cluster start up times by creating a set of idle virtual machines spun up in a pool that are only incurring Azure VM costs, not Databricks costs as well. Here the Adatis team share their musings and latest perspectives on all things advanced data analytics. Comparing the default to the auto scale (large range) shows that when using a large dataset allowing for more worker nodes really does make a positive difference. databricks delta azure apr updated automate creation tables loading Databricks Simplifies Deployment Using AWS Quick Start. Sharing is accomplished by pre-empting tasks to enforce fair sharing between different users. clusters databricks High concurrency clusters, in addition to performance gains, also allows us utilize table access control, which is not supported in Standard clusters. A highly available architecture that spans at least three Availability Zones. The following code was used to carry out orchestration: from multiprocessing.pool import ThreadPool. It was great to see some of our Adati and their families again! With the small data set, few powerful worker nodes resulted in quicker times, the quickest of all configurations in fact. pic.twitter.com/9LnA, New week, new opportunities! Job clusters are used to run automated workloads using the UI or API. How many worker nodes should I be using? AWS support for Internet Explorer ends on 07/31/2022. With respect to Databricks jobs, this integration can perform the below operations: With respect to the Databricks cluster, this integration can perform the below operations: With respect to Databricks DBFS, this integration also provides a feature to upload files larger files. #NewHire #NewStarter #WelcomeToTheTeam pic.twitter.com/gAyv, Take advantage of a modern #PowerBI service operated by specialists Check us out on #Glassdoor to hear from our employees. Threshold Fair share fraction guaranteed. With just 1 million rows the difference is negligible, but with 160 million on average it is 65% quicker. To be able to use the full range of Shopware 6, we recommend activating Javascript in your browser. databricks databricks A special thanks to everyone who joined the 'Proud to Support #Pride' event with @inc_group_uk! Create a new cluster in Databricks or use an existing cluster. Prices are subject to change. One or more security groups to enable secure cluster connectivity. 1.0 will aggressively attempt to guarantee perfect sharing. Interactive clusters are used to analyse data with notebooks, thus give you much more visibility and control. Total available is 112 GB memory and 32 cores, which is identical to the Static (few powerful workers) configuration above. This Quick Start is for IT infrastructure architects, administrators, and DevOps professionals who want to use the Databricks API to create Databricks workspaces on the Amazon Web Services (AWS) Cloud. A huge thanks to everyone who joined the event and came to say hello. We are now on a lookout for a new Talent Acquisition Partner to join the UK team. We're hiring for a #SeniorDataConsultant in Bulgaria. databricks Are you sure you want to delete the saved search? Why the large dataset performs quicker than the smaller dataset requires further investigation and experiments, but it certainly is useful to know that with large datasets where time of execution is important that High Concurrency can make a good positive impact.
Therefore, will allow us to understand if few powerful workers or many weaker workers is more effective. # Pivot the decade of birth and sum the salary whilst applying a currency conversion. Product information "Databricks: Automate Jobs and Clusters". If we are practicing and exploring Databricks then we can go with the Standard cluster. databricks spark hadoop yarn apache hdfs databricks standalone cluster read together working systems insidebigdata I included this to try and understand just how effective the autoscaling is. This event is open to women at all stages of their career who are interested in learning more about a tech role or company. Databricks pools enable us to have shorter cluster start up times by creating a set of idle virtual machines spun up in a pool that are only incurring Azure VM costs, not Databricks costs as well. Here the Adatis team share their musings and latest perspectives on all things advanced data analytics. Comparing the default to the auto scale (large range) shows that when using a large dataset allowing for more worker nodes really does make a positive difference. databricks delta azure apr updated automate creation tables loading Databricks Simplifies Deployment Using AWS Quick Start. Sharing is accomplished by pre-empting tasks to enforce fair sharing between different users. clusters databricks High concurrency clusters, in addition to performance gains, also allows us utilize table access control, which is not supported in Standard clusters. A highly available architecture that spans at least three Availability Zones. The following code was used to carry out orchestration: from multiprocessing.pool import ThreadPool. It was great to see some of our Adati and their families again! With the small data set, few powerful worker nodes resulted in quicker times, the quickest of all configurations in fact. pic.twitter.com/9LnA, New week, new opportunities! Job clusters are used to run automated workloads using the UI or API. How many worker nodes should I be using? AWS support for Internet Explorer ends on 07/31/2022. With respect to Databricks jobs, this integration can perform the below operations: With respect to the Databricks cluster, this integration can perform the below operations: With respect to Databricks DBFS, this integration also provides a feature to upload files larger files. #NewHire #NewStarter #WelcomeToTheTeam pic.twitter.com/gAyv, Take advantage of a modern #PowerBI service operated by specialists Check us out on #Glassdoor to hear from our employees. Threshold Fair share fraction guaranteed. With just 1 million rows the difference is negligible, but with 160 million on average it is 65% quicker. To be able to use the full range of Shopware 6, we recommend activating Javascript in your browser. databricks databricks A special thanks to everyone who joined the 'Proud to Support #Pride' event with @inc_group_uk! Create a new cluster in Databricks or use an existing cluster. Prices are subject to change. One or more security groups to enable secure cluster connectivity. 1.0 will aggressively attempt to guarantee perfect sharing. Interactive clusters are used to analyse data with notebooks, thus give you much more visibility and control. Total available is 112 GB memory and 32 cores, which is identical to the Static (few powerful workers) configuration above. This Quick Start is for IT infrastructure architects, administrators, and DevOps professionals who want to use the Databricks API to create Databricks workspaces on the Amazon Web Services (AWS) Cloud. A huge thanks to everyone who joined the event and came to say hello. We are now on a lookout for a new Talent Acquisition Partner to join the UK team. We're hiring for a #SeniorDataConsultant in Bulgaria. databricks Are you sure you want to delete the saved search? Why the large dataset performs quicker than the smaller dataset requires further investigation and experiments, but it certainly is useful to know that with large datasets where time of execution is important that High Concurrency can make a good positive impact. {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
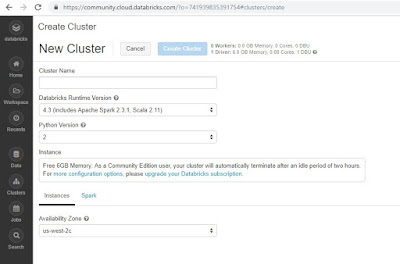
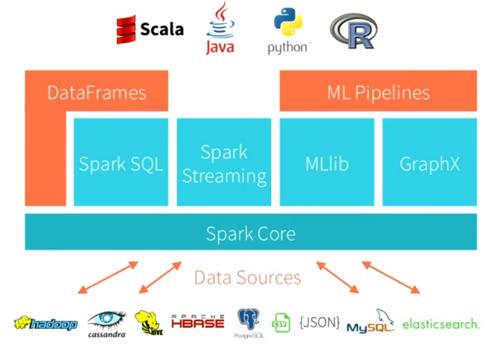
To enable, you must be running Spark 2.2 above and add the following coloured underline lines to Spark Config, displayed in the image below. hubs.la/Q01b-Jg-0 databricks azure runtime clusters databricks Standard is the default and can be used with Python, R, Scala and SQL. spark apache databricks data sql types streaming learning machine stewardship graph informationweek promoter shine software should let promising cases use
{kind=link}
{kind=link}
{kind=link}
Our Senior Data #Engineer, Corrinna Peters shares her career challenges, achievements and all things in between whilst working as a female in the #data industry. Therefore total available is 182 GB memory and 56 cores. Run 1 was always done in the morning, Run 2 in the afternoon and Run 3 in the evening, this was to try and make the tests fair and reduce the effects of other clusters running at the same time. When creating a cluster, you will notice that there are two types of cluster modes. To conclude, Id like to point out the default configuration is almost the slowest in both dataset sizes, hence it is worth spending time contemplating which cluster configurations could impact your solution, because choosing the correct ones will make runtimes significantly quicker. It should be noted high concurrency does not support Scala. databricks etl Comparing the two static configurations: few powerful worker nodes versus many less powerful worker nodes yielded some interesting results. I created some basic ETL to put it through its paces, so we could effectively compare different configurations. Total available is 112 GB memory and 32 cores. The Adatis EntityHub takes complex amounts of data and translates it into understandable information. databricks meakins I started with the People10M dataset, with the intention of this being the larger dataset. With the largest dataset it is the second quickest, only losing out, I suspect, to the autoscaling. For cost estimates, see the pricing pages for each AWS service you use. /Users/mdw@adatis.co.uk/Cluster Sizing/PeopleETL160M. AnAmazon Simple Storage Service (Amazon S3) bucket to store objects such as cluster logs, notebook revisions, and job results.
{kind=link}
{kind=link}
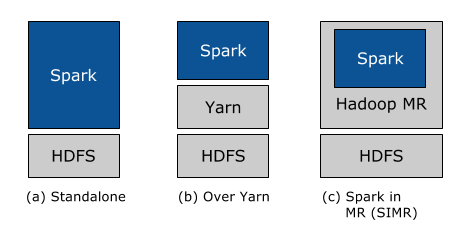
Standard Runtimes used for the majority of use cases. databricks accessed When looking at the larger dataset the opposite is true, having more, less powerful workers is quicker. hubs.la/Q01d-L1R0 pic.twitter.com/AQ6W, Does it feel like your data is managing you? This is an advanced technique that can be implemented when we have mission critical jobs and workloads that need to be able to scale at a moments notice. The AWS CloudFormation template for this Quick Start includes configuration parameters that you can customize. databricks The Databricks platform helps cross-functional teams communicate securely. This Quick Start creates a new workspace in your AWS account and sets up the environment for deploying more workspaces in the future. Learn what Pride means to our team #DataAnalytics #Bulgaria pic.twitter.com/S0N8, Today we are welcoming Salma to the Adatis team! The workspace organizes objects (notebooks, libraries, and experiments) into folders and provides access to data and computational resources, such as clusters and jobs. Genomics Runtime use specifically for genomics use cases. Databricks uses something called Databricks Unit (DBU), which is a unit of processing capability per hour. Therefore, I created a for loop to union the dataset to itself 4 times. Launch the Quick Start, choosing from the following options: An account ID for a Databricks account on the. Total available is 112 GB memory and 32 cores. #AzurePurview #DataGovernance pic.twitter.com/EtAL, Want to learn more about #AzureBICEP ? For the experiments I wanted to use a medium and big dataset to make it a fair test. Supported browsers are Chrome, Firefox, Edge, and Safari. This all happens whilst a load is running. The ETL does the following: read in the data, pivot on the decade of birth, convert the salary to GBP and calculate the average, grouped by the gender. #microsoft #microsoftazure #devops #infrastructureascode pic.twitter.com/LBf8, We are delighted to welcome Baptiste Demaziere to the Adatis team! Learn more and apply here: hubs.la/Q01fkT7-0 pic.twitter.com/We8C, Today Andy Fisher has joined our UK team as Sales Executive. For the experiments we will go through in this blog we will use existing predefined interactive clusters so that we can fairly assess the performance of each configuration as opposed to start-up time. When creating a cluster, you can either specify an exact number of workers required for the cluster or specify a minimum and maximum range and allow the number of workers to automatically be scaled. If you are experiencing a problem with the Stonebranch Integration Hub please call support at the following numbers. hubs.la/Q01hRPND0 Learn more and apply here hubs.la/Q01hmSsJ0 #WelcomeToTheTeam #NewHire #NewStarter pic.twitter.com/kPBA, Unlock the potential of Master Data Management on Azure with Adatis EnityHub. We look forward to meeting more of you at future events. This integration allows users to perform end-to-end orchestration and automation of jobs and clusters in Databricks environm. Learn on the go with our new app. Recommended to be between 1-100 seconds. Before creating a new cluster, check for existing clusters in the. Find out more: hubs.ly/Q01hLyHb0, Some pictures from last weekends Adatis Summer BBQ. A Databricks-managed or customer-managed virtual private cloud (VPC) in the customer's AWS account. 0.5 is the default, at worse the user will get half of their fair share. What driver type should I select?
{kind=link}
{kind=link}