This makes it impossible to build a generic data schema, without which the subsequent steps become unfeasible. If this happens, it is difficult for R&D personnel to adapt their technology stacks to the amount and speed of data growth. If thats the case, what is the persistent storage layer? Business demands always evolve along with business growth.
3. Data Access: Determine the data sources to be accessed and complete full data extraction and incremental data access. For example, Amazon Athena and Amazon Redshift provide SQL-based interactive batch processing capabilities, and Amazon EMR provides Spark-based computing capabilities, such as stream computing and machine learning. The merchant can synchronize its full tracking data and the data schema to the data lake, and also archive daily incremental data to the data lake in T+1 mode. AWS effectively implements all its services in the ecosystem. The real-time stream computing model is essential for the online businesses of many Internet companies. You can also use business intelligence (BI) report tools and dashboards to directly access the data in a data lake. Figure 3 shows the Lambda architecture. This ensures data mobility. Quality management and data governance are closely related to the organizational structure and business type of an enterprise, requiring a great deal of customization and development work. Both DLA and AnalyticDB inherently support OSS access. A series of components have been developed for HDFS and MR. The analyzed data can be used for basic analytics functions, such as behavior statistics, customer profiling, customer selection, and ad serving monitoring. The two approaches are briefly summarized here: 1. Bill Inmon proposed the bottom-up approach, in which a data warehouse is built using the enterprise data warehouse and data mart (EDW-DM) model. You need to get different business stakeholders interested and show some successes for your data lake environment to flourish, as the success of any IT platform ultimately is based upon business adoption. DLA can be viewed as the near-source layer of a scalable data warehouse. A data warehouse can be built by using bottom-up and top-down approaches, which were proposed by Bill Inmon and Ralph Kimball, respectively. The metadata in AWS Glue is accessible to Amazon Kinesis. Support for multi-modal computing engines, such as SQL, batch processing, stream computing, and machine learning, 3 . The boundary of a lake is analogous to an enterprise or organization's business boundary. Integrated data lake management solutions like Bedrock and Mica are now delivering the necessary controls without making Hadoop as slow and inflexible as its predecessor solutions. Here is a checklist of what you need to make sure you are doing so in a controlled yet flexible way. This meets the needs of elastic analytics and significantly lowers O&M costs and operational costs. Figure 16 shows the architecture of DG's transformed advertising data lake solution. Keep in mind that this is a long-term investment, so you need to think carefully about where the technology is moving. DMS manages data at four granularities, database, table, column, and row, providing control over data security required by enterprises. With DIS, DLI defines all types of data points, which can be used by Flink jobs as sources or sinks. Depending on the business criticality of your data lake, and of the different SLAs you have in place with your different user groups, you need a disaster recovery plan that can support it. Figure 21: SaaS-Based Data Intelligence Service Model Supported by a Data Lake.

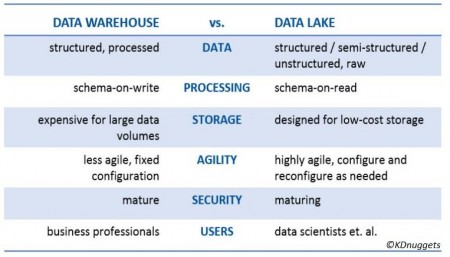
Figure 7 shows four phases from left to right: data inflow, data accumulation, data computing, and data application. Amazon Kinesis is a stream computing service that provides Kinesis Data Firehose to create a fully managed data distribution service. The global data lake market was valued at $7.9 billion in 2019 and is expected to grow at a compound annual growth rate (CAGR) of 20.6 percent by 2024 to reach $20.1 billion. If you understand DLI differently, you are welcome to share your views. Deploy custom Alibaba Cloud solutions for business-critical scenarios with Quick Start templates. An EDW is an enterprise- or organization-wide generic data schema, which is not suitable for direct data analytics performed by upper-layer applications. The industry already has many universal practices for data lake technology selection. The solution also introduces QuickBI in the frontend for visual analysis. One exception is that AWS Glue accesses AWS Lake Formation only at the database and table levels. A data lake requires a wide range of computing capabilities to meet your business needs. For example, TensorFlow and PyTorch can be trained on sample data from the Hadoop Distributed File System (HDFS), Amazon S3, or Alibaba Cloud Object Storage Service (OSS). The combination of big data and artificial intelligence (AI) gave birth to a variety of machine learning and deep learning algorithms. Data flows from left to right. You need proper SLAs in terms of lack of downtime, and in terms of data being ingested, processed, and transformed in a repeatable manner. 2. Data Flexibility: As shown in the "Schema" row of the preceding table, schema-on-write or schema-on-read indicates the phase in which the data schema is designed. That is all that needs to be done in the data analysis step. Alibaba Cloud experts provide retailers with a lightweight and customized big data consulting service to help you assess your big data maturity and plan your big data journey. Azure's data lake solution consists of the data lake storage layer, interface layer, resource scheduling layer, and computing engine layer, as shown in Figure 15 (source: Azure website.) I would like to thank Nanjing for compiling the cases in Section 5.1 of this article and thank Xibi for his review. Oriented toward data, a data lake can retrieve and store full data of any type and source at any speed and scale. Before starting to plan a data lake, we must answer the following key questions: First, I want to look at the data lake definitions provided by Wikipedia, Amazon Web Services (AWS), and Microsoft.

How to build, maintain, and derive value from your Hadoop data lake. Early use cases for Hadoop were trumpeted as successes based on their low cost and agility. DLA uses OSS as its native storage, whereas AnalyticDB provides easy access to OSS's structured data through foreign tables. A data lake is the infrastructure for next-generation big data analytics and processing. DAYU generates quality rules and a transformation model based on the data schema and metric model. *Your comment will be reviewed before being published, Light Bulbs with DNA and Fluorescent Properties: BioLEDs, Sustainability Notes n2: Natural and Technological Solutions to Stop Climate Change, a data lake is designed to retain all attributes, Secure and Smart Internet of Things (IoT) Using Blockchain and AI, Big Data: Challenges, Opportunities and Exploitation, Data Analytics, Artificial Intelligence and Big Data in Banking, Your Smart Device Will Feel Your Pain & Fear, Ventana al Conocimiento (Knowledge Window).

http://emcplus.typepad.com/.a/6a0168e71ada4c970c01a3fcc11630970b-800wi, http://hortonworks.com/wp-content/uploads/2014/05/TeradataHortonworks_Datalake_White-Paper_20140410.pdf, Receive the OpenMind newsletter with all the latest contents published on our website, Universidad Autnoma de Madrid, Madrid, Spain, Prof. Ahmed Banafa. 4. Data Traceability: A data lake stores the full data of an organization or enterprise and manages the stored data throughout its lifecycle, from data definition, access, and storage to processing, analytics, and application. The DAYU data schema consists of the near-source layer, multi-source integration layer, and detail data layer. We can further analyze the characteristics of a data lake in terms of data and computing: 1. Data Fidelity: A data lake stores data as it is in a business system. Then, the engine writes the data processing results to OSS, a relational database management system (RDBMS), NoSQL database, or data warehouse as needed. Figure 12 illustrates Alibaba Cloud's data lake solution. The platform cannot provide a full range of SaaS-based analytics functions to meet the various customization needs of all types of merchants. Methods, Process, Examples, Techniques, Build a Cloud Data Lake Using E-MapReduce, Using Apache Spark for Data Processing and Analysis, MySQL Deep Dive - Implementation and Acquisition Mechanism of Metadata Locking, ClickHouse: Analysis of the Core Technologies behind Cloud Hosting to Cloud-Native, PolarDB-X Kernel V5.4.14: A New Version with More Refined Data Management Capabilities, Senior Technical Experts from Alibaba Discuss Data Warehouse Tuning Part 2, Senior Technical Experts from Alibaba Discuss Data Warehouse Tuning Part 1, Database Autonomy Services Lead the New Era of Database Autonomous Driving, Case Analysis of PostgreSQL Transaction Rollback, See the Past and Future of Redis from Redis 7.0, New-Gen Cluster Non-Inductive Data Migration of Alibaba Cloud In-Memory Database Tair, An In-depth Analysis of Atomicity in PolarDB, Commercially Available Data Lake Solutions. Frontend traffic optimization no longer works well. Alibaba Cloud's data lake solution is specially designed for data lake analytics and federated analytics. Almost all processing paradigms use the DAG-based workflow model and provide corresponding integrated development environments. These two steps form a data catalog and generate security settings and access control policies. Going back to the people and skills point, its critical to have the right people with experience managing these environments, to put together an operations team to support the SLAs and meet the business requirements. After all, the data lake needs to provide value that the business is not getting from its EDW. You must also think about multitenancy: certain users might not be able to share data with other users. AWS uses external computing engines to support rich computing modes apart from batch processing. Are you ready to build a data lake? Figure 20 shows the Software as a Service (SaaS) model of YM's data intelligence services. Compared with Figure 22, which illustrates the basic process of building a data warehouse or data mid-end, Figure 23 illustrates a five-step process for building a data lake in a simpler and more feasible manner: 1. Data Analysis: Analyze basic information about the data, including the data sources, data types, data forms, data schemas, total data volume, and incremental data volumes. Deployment options are going to increase, also, with companies that dont want to go into public clouds building private clouds within their environments, leveraging patterns seen in public clouds. A data lake adopts schema-on-read, meaning it sees business uncertainty as the norm and can adapt to unpredictable business changes. This helps you trace the entire production process of any data record. Most data lake practices recommend using distributed systems, such as Amazon S3, Alibaba Cloud OSS, OBS, and HDFS, as the data lake's unified storage. In terms of machine learning, Amazon SageMaker reads training data from Amazon S3 and then writes trained models back to Amazon S3. New computing models are constantly proposed to meet increasing needs for batch processing performance, resulting in computing engines, such as Tez, Spark, and Presto. You also need data scientists who will be consumers of the platform, and bring them in as stakeholders early in the process of building a data lake to hear their requirements and how they would prefer to interact with the data lake when it is finished. You need experts who have hands-on experience building data platforms and who have extensive experience with data management and data governance so they can define the policies and procedures upfront. Azure allows you to develop a custom data lake solution based on Visual Studio. Figure 23: Basic Data Lake Construction Process. This is one of the reasons why many fast-growing startups find it difficult to build a data warehouse or data mid-end to meet their needs. Organizations must be aware that data lakes will eventually become hybrids of data stores, include HDFS, no-SQL, and Graph DBs. Regardless of the source, most definitions of the data lake concept focus on the following characteristics of data lakes: In short, a data lake is an evolving and scalable infrastructure for big data storage, processing, and analytics. After migration, we integrated DLA and OSS to provide superior analytics capabilities for DG. It retrieves full and incremental data from data sources and stores the retrieved data in a standard manner. For many fast-growing game companies, a popular game often results in extremely fast data growth in a short time. The final results of batch processing and stream computing are provided to applications through the service layer, ensuring access consistency. In the era of big data, data has become a type of asset possessed by an enterprise or organization. Big data analytics is essential for the conversion from advertising traffic into sales. Business insights and abstraction can significantly promote the development and application of data lakes. Huawei Cloud provides the DAYU platform to better support advanced data lake functions, such as data integration, data development, data governance, and quality management. We see data lakes taking over EDWs as organizations attempt to be more agile and generate more timely insights from more of their data. The data processed by Kinesis Data streams in real-time can be easily written to Amazon S3 using Kinesis Data Firehose. DG is a leading global provider of intelligent marketing services to enterprises looking to expand globally. As shown in Figure 24, to apply the real-time stream computing model to the data lake, you can introduce Kafka-like middleware as the data forwarding infrastructure. Once you have the data lake platform in place, how will you advertise the fact and bring in additional users? In many cases, businesses are conducted through a trial-and-error exploration without a clear direction. Alibaba Cloud provides big data consulting services to help enterprises leverage advanced data technology. It is operational during setup and manageable during use. However, data warehouses do not support flexible data analytics and processing. A data lake is a type of big data infrastructure with an excellent total cost of operation (TCO) performance. Figure 7: Data Lake Solution Provided by AWS. 3. Data Manageability: A data lake provides comprehensive data management capabilities. Data Lake Analytics (DLA): An Interactive Analytics Service That Utilizes Serverless Architecture, Exploring Application and Analysis of Big Data in The Cloud, Quick Implementation of Data Lake House Based on MaxCompute, What is Data Analysis? A data lake is a technical solution that can solve these problems. Therefore, to meet the access needs of different applications, a data lake must support additional storage engines as well as core storage engines, such as Amazon S3, Alibaba Cloud OSS, OBS, and HDFS. Data warehouses help organizations become more efficient. To reduce the frequency of writing intermediate results from data processing, computing engines, such as Spark and Presto, cache data in the memory of compute nodes whenever possible. I recommend using the stream computing model illustrated in Figure 24. Azure implements YARN-based resource scheduling. The interface layer is WebHDFS, which provides an HDFS interface for Azure Object Storage. It stores structured, semi-structured, and unstructured data, It supports access to all types of disparate data sources, It discovers, manages, and synchronizes metadata, It provides the built-in SQL and Spark computing engines, which can process various types of data more effectively. The platform also provides unified data access and analytics services in SaaS mode. ETL tools are used to transfer data from data sources of an operational or transactional system to the data warehouse's operational data store (ODS). Before the transformation, YJ stored all its structured data in a max-specification MySQL database. For example, Amazon S3 stores raw data, NoSQL stores processed data that can be accessed in KV mode, and online analytical processing (OLAP) engines store data that is used to create reports in real-time or support ad hoc queries. The platform provides multi-client SDKs for merchants to access tracking data in diverse forms, such as webpages, apps, and mini programs. Lakes are naturally stratified to adapt to different ecosystems. The Lambda and Kappa architecture diagrams were sourced from the Internet. In terms of the total cost of ownership (TCO) for ad serving and analytics, DLA provides serverless elastic services that are billed in pay-as-you-go mode, with no need to purchase fixed resources. What are the differences between a data lake and a big data platform? Unlike traditional data warehouses, which are optimized for data analysis by storing only some attributes and dropping data below the level aggregation, a data lake is designed to retain all attributes, especially when you do not yet know what the scope of data or its use. There is a core logic behind data analytics. As shown in Figure 2, Hadoop is a batch data processing infrastructure that uses HDFS as its core storage and MapReduce (MR) as the basic computing model. You can store your data as-is, without having to first structure the data, and run different types of analyticsfrom dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions. This architecture had the following problems: Our analysis showed that YJ's architecture was a prototype of a data lake because full data is stored in OSS. Due to its fidelity and flexibility, a data lake stores at least two types of data: raw data and processed data. You should follow three basic principles: separation of computing and storage, elasticity, and independent extensions. It also integrates seamlessly with operational stores and data warehouses so you can extend current data applications. Once you have the business alignment and you know what your priorities are, you need to define the upfront architecture: what are the different components you will need, and what will the end technical platform look like? See our statement of editorial independence. This would allow it to better deal with traffic peaks and valleys. AWS's data lake solution provides stream computing and machine learning only as extended computing capabilities rather than required capabilities, but you can easily integrate them with the solution. The DAG model improves computing models' abstract concurrency. This achieves a balance between data storage capacity and cost. AWS's data lake solution provides all of the functions shown in the reference architecture except quality management and data governance. Just as you must think of metadata from an enterprise-wide perspective, you need to be able to integrate your data lake with external tools that are part of your enterprise-wide data view. Behavior data and structured data are separated and cannot be associated for analysis, Intelligent behavior data retrieval was supported, but deep data mining and analytics services were not, OSS was only used for data storage and its deeper data value was not utilized. In addition, DMs are difficult to integrate. Specifically, a data lake not only provides sufficient storage and computing capabilities for an increasing amount of data but also constantly provides new data processing models to meet emerging needs. I could not find a diagram of DLI's overall architecture on the Huawei website, so I tried to draw one based on my knowledge. It seems that there has been an error in the communication. Download the full report Architecting Data Lakes by Alice LaPlante and Ben Sharma to learn more. We've drawn on the experience of working with enterprise customers and running some of the largest scale processing and analytics in the world for Microsoft businesses like Office 365, Xbox Live, Azure, Windows, Bing, and Skype. Big data platforms process the full data of an enterprise or organization while providing a full range of data processing capabilities to meet application needs. In terms of computing power, current mainstream data lake solutions support SQL batch processing and programmable batch processing. Since business changes are unpredictable, you can always keep data as-is and process data as needed. Data lake-related products available on the Huawei website include Data Lake Insight (DLI) and an intelligent data lake operations platform called DAYU. The types of analyses that were previously only possible on costly proprietary software and hardware combinations as part of cumbersome EDWs are now being leveraged by organizations of all types and sizes simply by deploying free open source software on commodity hardware clusters.