 The algorithm comes up with the probability that a specific unit belongs to one possible class, then a classification rule is employed to assign a single class to each individual. Subtracting the Expected Accuracy we are also removing the intrinsic dissimilarities of different datasets and we are making two different classification problems comparable. If we are interested in achieving good predictions (i.e. Such metrics may have two different specifications, giving rise to two different metrics: Micro F1-Score and Macro F1-Score [opitz2019macro]. It is important to remove the Expected Accuracy (the random agreement component for Cohen and the two independent components for us) from the Accuracy for two reasons: the Expected Accuracy is related to a classifier that assigns units to classes completely at random, it is important to find a models Prediction that is as dependent as possible to the Actual distribution. Many metrics come in handy to test the ability of a multi-class classifier.
The algorithm comes up with the probability that a specific unit belongs to one possible class, then a classification rule is employed to assign a single class to each individual. Subtracting the Expected Accuracy we are also removing the intrinsic dissimilarities of different datasets and we are making two different classification problems comparable. If we are interested in achieving good predictions (i.e. Such metrics may have two different specifications, giving rise to two different metrics: Micro F1-Score and Macro F1-Score [opitz2019macro]. It is important to remove the Expected Accuracy (the random agreement component for Cohen and the two independent components for us) from the Accuracy for two reasons: the Expected Accuracy is related to a classifier that assigns units to classes completely at random, it is important to find a models Prediction that is as dependent as possible to the Actual distribution. Many metrics come in handy to test the ability of a multi-class classifier. Although, using the units all together ends up in having the Grand Total in both the Formulas. Therefore, Cross-Entropy does not evaluate the goodness of the classification rule (the rule which translates the probabilities into the predicted class). Classification tasks in machine learning involving more than two classes are known by the name of "multi-class classification". There are many different solutions, however each one shares a common factor: they use available data (X variables) to obtain the best prediction ^Y of the outcome variable Y. In this way, we have obtained an Accuracy value related only to the goodness of the model and we have already deleted the part ascribed to chance (the Expected Accuracy).
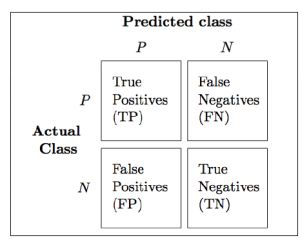
 Given this definition of independence between categorical variables, we can start dealing with Cohens Kappa indicators as rating values of the dependence (or independence) between the models Prediction and the Actual classification. When the class presents a high number of individuals (i.e. For the required computations, we will use the Confusion Matrix focusing on one class at a time and labelling the tiles accordingly. In the event that there is less agreement between the raters than expected by chance, the metric may go below 0. Therefore, the Accuracy gives different importance to different classes, based on their frequency in the dataset. AUC values closer to 1 are. In this last case the issue changes his name and is called "multi-class classification". Taking a look to the formula, we may see that Micro-Average F1-Score is just equal to Accuracy. In Formula 24, we notice that MCC takes into account all the confusion matrix cells. Only in the 2000s MCC became a widely employed metric to test the performance of Machine Learning techniques with some extensions to the multi-class case [Chicco2020].
Given this definition of independence between categorical variables, we can start dealing with Cohens Kappa indicators as rating values of the dependence (or independence) between the models Prediction and the Actual classification. When the class presents a high number of individuals (i.e. For the required computations, we will use the Confusion Matrix focusing on one class at a time and labelling the tiles accordingly. In the event that there is less agreement between the raters than expected by chance, the metric may go below 0. Therefore, the Accuracy gives different importance to different classes, based on their frequency in the dataset. AUC values closer to 1 are. In this last case the issue changes his name and is called "multi-class classification". Taking a look to the formula, we may see that Micro-Average F1-Score is just equal to Accuracy. In Formula 24, we notice that MCC takes into account all the confusion matrix cells. Only in the 2000s MCC became a widely employed metric to test the performance of Machine Learning techniques with some extensions to the multi-class case [Chicco2020]. In Multi-class classification, we may regard the response variable Y and the prediction ^Y as two discrete random variables: they assume values in {1,,K} and each number represents a different class. The quadratic weighted kappa is calculated between the scores which are expected/known and the predicted scores. Hand & Robert J. Till proposed in 2001 a simple generalization of the Area Under the ROC Curve for Multiple Class Classification Problems [source], you made some mistake with validation and should revisit data processing, and holdout pipeline of yours. A perfect model would have a log loss of 0. Referring to confusion matrix in Figure 2, since Precision and Recall do not consider the True Negative elements, we calculate the binary F1-Score as follows: The F1-Score for the binary case takes into account both Precision and Recall. Whereas, the least possible score is -1 which is given when the predictions are furthest away from actuals. Instead, when the class has just few individuals (i.e. Considering the generic i-th unit of the dataset: it has specific values (x(i)1,,x(i)m) of the X variables and the number y(i) represents the class the unit belongs to. Most of the time, it means that, AUC = 0 implies that your model is very bad (or very good!). AUC often comes up as a more appropriate performance metric than accuracy in various applications due to its appealing properties, e.g., insensitivity toward label distributions and costs. The prediction task is also called "classification problem" when the outcome represents different classes, otherwise is called "regression problem" when the outcome is a numeric measurement. Matthews Correlation Coefficient takes advantage of the Phi-Coefficient [MATTHEWS1975442], while Cohens Kappa Score relates to the probabilistic concept of dependence between two random variables. class "a"), the models bad performance on this last class cannot be caught up by Accuracy. If you didnt make any mistakes, then, congratulations, you have the best model one can have for the dataset you, the probabilities for the predictions, for example, if your probability for the, positive class is p, try substituting it with 1-p. As an example, we consider Model A with Precision equal to Recall (80%), and Model B whose precision is 60% and recall is 100%. As the most famous classification performance indicator, the Accuracy returns an overall measure of how much the model is correctly predicting the classification of a single individual above the entire set of data. So Cohens Kappa results to be a measure of how much the models prediction is dependent on the Actual distribution, with the aim to identify the best learning algorithm of classification. It is possible to compare two categorical variables building the confusion matrix and calculating the marginal rows and the marginal columns distributions. In the multi-class case, the Matthews correlation coefficient can be defined in terms of a confusion matrix C for K classes. 0.4, but, substantially, they have different performance on the aggregate perspective: in Panel (a)a the highest probability class is 2, for (b)b it is 6. In order to obtain Micro F1-Score, we need to compute Micro-Precision and Micro-Recall before. In Figure 5, a representation of the two distributions, for a fictitious unit. Quadratic Weight Kappa is also called Weighted Cohens Kappa. In the following figures we will regard respectively p(yi) and p(^yi) as the probability distributions of the conditioned variables above. First, create a multi class confusion matrix O between predicted and actual ratings. Generally a score of 0.6+ is considered to be a really good score. Accuracy returns an overall measure of how much the model is correctly predicting on the entire set of data. When we switch from one class to another one, we compute the quantities again and the labels for the Confusion Matrix tiles are changed accordingly. When we think about classes instead of individuals, there will be classes with a high number of units and others with just few ones. We invite you to read the excellent book Approaching (Almost) Any Machine Learning Problem. we have noticed that the Expected Accuracy Pe plays the main role in the Cohens Kappa Score because it brings with it two components of independence (PPositive and PNegatives) which are subtracted from the observed agreement Po. The formula of the Balanced Accuracy is essentially an average of recalls. There is no link to the class size, because classes with different size are equally weighted at the numerator. In fact, this metric allows to keep separate algorithm performances on the different classes, so that we may track down which class causes poor performance. Cohens Kappa finds useful applications in many classification problems. Strong correlation implies that the two variables strongly agree, therefore the predicted values will be very similar to the Actual Classification. The quadratic weighted kappa is calculated as follows. Balanced Accuracy is another well-known metric both in binary and in multi-class classification; it is computed starting from the confusion matrix. From a theoretical point of view, Cross-Entropy is used to evaluate the similarity between two distribution functions. Instead K is negative when the agreement between the algorithm and the true labels distribution is worse than the random agreement, so that there is no accordance between the models Prediction and the Actual classification. Although, it takes into account only the true class probability p(^yi=k) without caring about the probability mass distribution among the remaining classes. In particular, the numerator consists of two products including all the four inner cells of the confusion matrix in Figure 7, while the denominator consists of the four outer cells (row totals and column totals). We have introduced multi classification metrics, those implemented in Prevision.io. The same reasoning is also valid for the multi-class case. At the same time, it keeps track of the importance of each class thanks to the frequency.
From an algorithmic standpoint, the prediction task is addressed using the state of the art mathematical techniques. When evaluating and comparing machine learning algorithms on multi class targets, performance metrics are extremely valuable. MCC has a range of [1,1]. The Formulas 12 and 13 represent the two quantities for a generic class k. Macro Average Precision and Recall are simply computed as the arithmetic mean of the metrics for single classes. The difference is mainly due to the weighting that recall applies on each row/actual class. This also means that Balanced Accuracy is insensitive to imbalanced class distribution and it gives more weight to the instances coming from minority classes. In this white paper we review a list of the most promising multi-class metrics, we highlight their advantages and disadvantages and show their possible usages during the development of a classification model. Most. Cohen (1960) evaluated the classification of two raters (i.e.
Firstly it allows the joint comparison of two models for which it has registered the same accuracy, but different values of Cohens Kappa. AveP(q) is the average precision (AP) for a given query q. Also F1-Score assesses classification models performance starting from the confusion matrix, it aggregates Precision and Recall measures under the concept of harmonic mean. As a simple arithmetic mean of Recalls, the Balanced Accuracy gives the same weight to each class and its insensibility to class distribution helps to spot possible predictive problems also for rare and under-represented classes.
This ensures to obtain a reliable value of the overall performance on the dataset: we may interpret this metric as the probability to correctly predict a given unit, even if the formula is slightly different from the Accuracy. In a multi-classification problem, we define the logarithmic loss function F in terms of the logarithmic loss function per label Fi as: The cost function F measures the distance between two probability distributions, i.e.
The performance on the smallest ones is less important, because of their low weight. comparing the performance of two different models or analysing the behaviour of the same model by tuning different parameters. Each class is considered in the formula above, however the quantity p(Yi=k|Xi) is 0 for all the classes except the true one, making all the terms but one disappear.